Raft原理及其实现 Part 3
持久化
持久化的目的是当服务重启时,使用持久化的数据将节点的状态从之前的工作状态恢复到当前状态。在 Raft 中,我们只需要将 votedFor 、 currentTerm 和 log 持久化到磁盘即可。
- votedFor:如果这些数据没有被持久化,就会导致同一个节点在同一任期内对多个候选人进行投票。
- currentTerm:currentTerm 至关重要,它确保每个任期最多选出一位 Leader。如果节点在不知道当前任期的情况下重启,它将无法在投票过程中正确增加其任期。
- 日志:日志包含应用于状态机的命令的历史记录,这对于节点恢复其状态至关重要。
至于其他字段,最终还是通过心跳机制来恢复。
代码实现
func (rf *Raft) persist() {
// Your code here (2C).
// Example:
// w := new(bytes.Buffer)
// e := labgob.NewEncoder(w)
// e.Encode(rf.xxx)
// e.Encode(rf.yyy)
// raftstate := w.Bytes()
// rf.persister.Save(raftstate, nil)
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.votedFor)
e.Encode(rf.currentTerm)
e.Encode(rf.log)
e.Encode(rf.lastIncludedIndex)
e.Encode(rf.lastIncludedTerm)
raftstate := w.Bytes()
rf.persister.Save(raftstate, rf.snapshot)
}只要 votedFor、currentTerm、log 中的任何一个被修改,我们就会调用 rf.persist() 。当我们启动一个 Raft 节点时,我们需要从磁盘恢复状态。
func Make(peers []*labrpc.ClientEnd, me int, persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
// codes ...
rf.readPersist(persister.ReadRaftState())
// codes ...
return rf
}Snapshot 快照
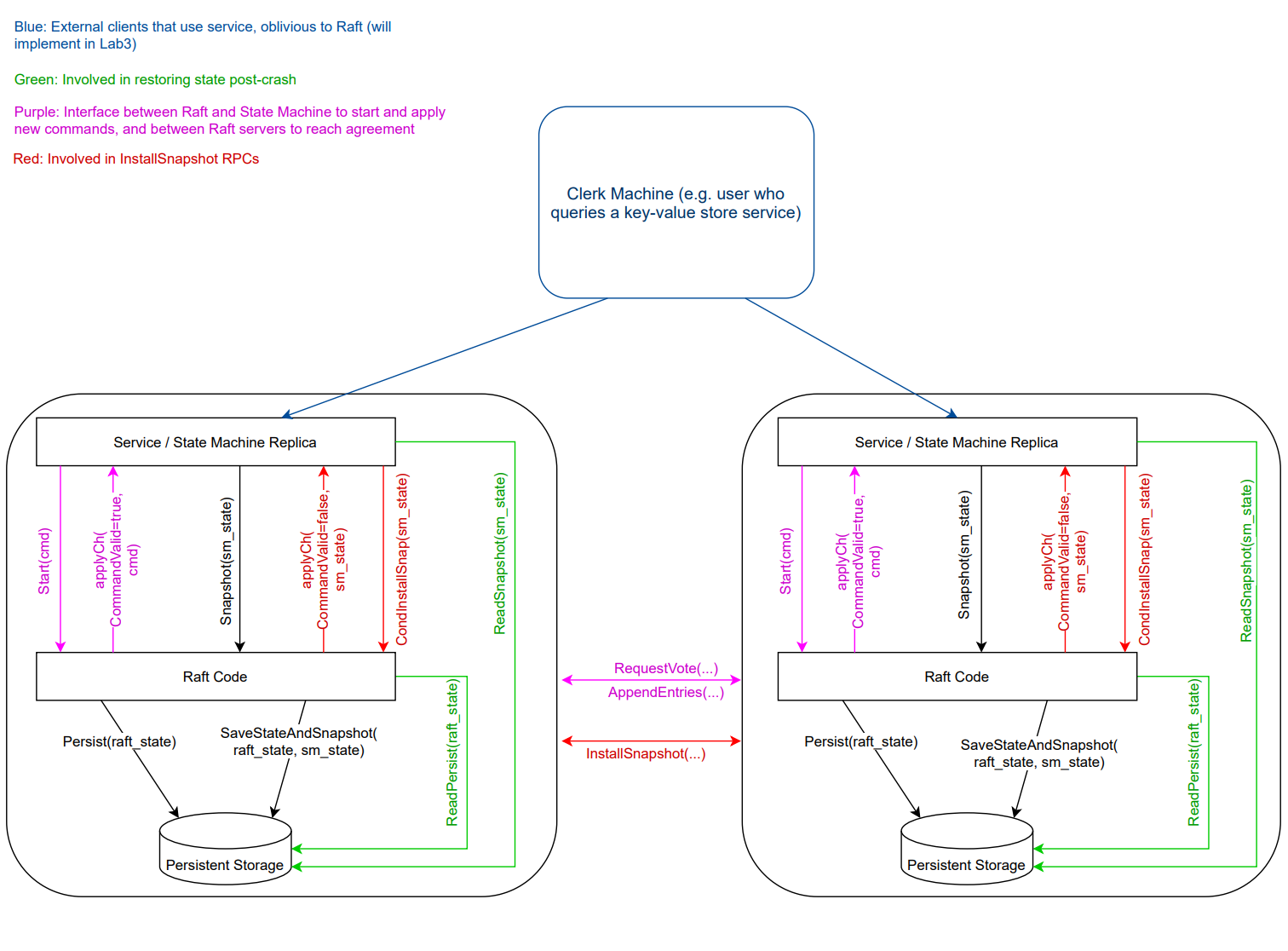
- 当日志变得太大时执行快照。
- 使用
SaveStateAndSnapshot()将快照的数据持久化。 - 如果Follower的日志落后于Leader,Leader则通过
InstallSnapshotRPC 发送快照。 - Follower用快照更新他们的状态并丢弃旧的日志。
- 服务崩溃后重启时使用
ReadPersist()和ReadSnapshot()从快照恢复。
代码实现
persist and readPersist
我们需要修改 persist() 和 readPersist() 函数来支持快照。Raft 结构中新增了三个字段:
lastIncludedIndex: 最新的快照包含的Index,此索引及之前的数据都可以抛弃。lastIncludedTerm: 同上,不过是包含的任期。snapshot: 快照本身的数据。
func (rf *Raft) persist() {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
// codes ...
e.Encode(rf.lastIncludedIndex)
e.Encode(rf.lastIncludedTerm)
raftstate := w.Bytes()
rf.persister.Save(raftstate, rf.snapshot)
}
func (rf *Raft) readPersist(data []byte) {
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
// codes ...
var lastIncludedIndex int
var lastIncludedTerm int
d.Decode(&lastIncludedIndex)
d.Decode(&lastIncludedIndex)
// codes ...
rf.lastIncludedIndex = lastIncludedIndex
rf.lastIncludedTerm = lastIncludedTerm
}当我们启动一个 Raft 节点时,我们需要从磁盘恢复状态。
func Make(peers []*labrpc.ClientEnd, me int, persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
// codes ...
rf.snapshot = persister.ReadSnapshot()
rf.readPersist(persister.ReadRaftState())
// codes ...
return rf
}Index
应用快照后,快照之前的日志数据将被丢弃(压缩),这意味着此后的日志索引与原始索引下标相比发生了变化。我们需要将全局索引转换为本地索引,反之亦然,这样可以提高代码的可读性。
我们用全局索引来表示原有的索引(也就是没有快照的时候),用本地索引来表示引入快照后的索引。
func (rf *Raft) toGlobalIndex(localIndex int) int {
return rf.lastIncludedIndex + localIndex
}
func (rf *Raft) toLocalIndex(globalIndex int) int {
return globalIndex - rf.lastIncludedIndex
}有了全局索引和局部索引,代码会遵循以下规则:
rf.log始终使用本地索引- 在其他情况下,使用全局索引(比如节点间通信)
Snapshot()
当我们从客户端收到快照时,我们需要更新 lastIncludedIndex 、 lastIncludedTerm 和 log 。
func (rf *Raft) Snapshot(index int, snapshot []byte) {
// Your code here (2D).
rf.mu.Lock()
defer rf.mu.Unlock()
if index > rf.commitIndex || index <= rf.lastIncludedIndex {
return
}
rf.snapshot = snapshot
lastIncludeEntry := rf.log[rf.toLocalIndex(index)]
// log in index 0 is a placeholder, corresponding to lastIncludedEntry
rf.log = rf.log[rf.toLocalIndex(index):]
// update lastIncludedIndex and lastIncludedTerm after truncating the log
rf.lastIncludedIndex = index
rf.lastIncludedTerm = lastIncludeEntry.Term
if rf.lastApplied < rf.lastIncludedIndex {
rf.lastApplied = rf.lastIncludedIndex
}
logger.Printf(rf, Snapshot, "Received snapshot no longer need index <= %v, current log %v", index, rf.log)
rf.persist()
}InstallSnapshot() 函数
如果 Follower 的日志远远落后于 Leader 的日志,并且 args.PrevLogIndex < rf.lastIncludedIndex,则表示 Leader 不再拥有该 Follower 所需的日志条目,因为这些条目已经被压缩成快照。在这种情况下,Leader 必须向 Follower 发送 InstallSnapshot RPC,允许 Follower 通过应用快照来将其状态与 Leader 同步。
func (rf *Raft) SyncLogHeartbeat() {
for !rf.killed() {
rf.mu.Lock()
// codes ...
for serverId := 0; serverId < len(rf.peers); serverId++ {
if serverId == rf.me {
continue
}
prevLogIndex := rf.nextIndex[serverId] - 1
args := &AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevLogIndex,
LeaderCommit: rf.commitIndex,
}
// behind too much, send snapshot
if args.PrevLogIndex < rf.lastIncludedIndex {
logger.Printf(rf, Snapshot, "sending snapshot to server %v, args=%v", serverId, args)
go rf.handleInstallSnapshot(serverId)
}
}
rf.mu.Unlock()
time.Sleep(time.Duration(HeartbeatTimeout) * time.Millisecond)
}
}InstallSnapshot() 函数通过应用接收到的快照来处理其与 Leader 的状态同步。
- 如果快照的
LastIncludedIndex和LastIncludedTerm与现有的日志条目匹配,则 Follower 保留后续条目; - 否则,它将丢弃整个日志并初始化新日志。
Follower更新自己的 Snapshot、lastIncludedIndex 和 lastIncludedTerm,并调整其 commitIndex 和 lastApplied(如果它们落后于快照的 LastIncludedIndex)。
然后通过 applyCh 通道发送 ApplyMsg 将快照应用到状态机。
最后,Follower持久化自己的状态。
func (rf *Raft) InstallSnapshot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
// codes ...
// 6. If existing log entry has same index and term as snapshot’s last included entry, retain log entries following it and reply
hasEntry := false
localLogIndex := 0
for ; localLogIndex < len(rf.log); localLogIndex++ {
if rf.toGlobalIndex(localLogIndex) == args.LastIncludedIndex && rf.log[localLogIndex].Term == args.LastIncludedTerm {
hasEntry = true
break
}
}
// 7. Discard the entire log
if hasEntry {
rf.log = rf.log[localLogIndex:]
} else {
// log in index 0 is a placeholder
rf.log = []LogEntry{{Term: rf.lastIncludedTerm, Command: nil}}
}
rf.snapshot = args.Data
rf.lastIncludedIndex = args.LastIncludedIndex
rf.lastIncludedTerm = args.LastIncludedTerm
if rf.commitIndex < args.LastIncludedIndex {
rf.commitIndex = args.LastIncludedIndex
}
if rf.lastApplied < args.LastIncludedIndex {
rf.lastApplied = args.LastIncludedIndex
}
reply.Term = rf.currentTerm
msg := &ApplyMsg{
SnapshotValid: true,
Snapshot: args.Data,
SnapshotTerm: args.LastIncludedTerm,
SnapshotIndex: args.LastIncludedIndex,
}
rf.applyCh <- *msg
logger.Printf(rf, Snapshot, "install snapshot, lastIncludedIndex=%v, lastIncludedTerm=%v, current lastApplied=%v", rf.lastIncludedIndex, rf.lastIncludedTerm, rf.lastApplied)
rf.persist()
}商业转载请联系站长获得授权,非商业转载请注明本文出处及文章链接,您可以自由地在任何媒体以任何形式复制和分发作品,也可以修改和创作,但是分发衍生作品时必须采用相同的许可协议。