Raft原理及其实现 Part 2
日志复制
在 MIT 6.5840 实验中, 客户端通过Start函数向所有Raft节点发送Command。
- 如果该节点不是Leader,它将立即返回 false。
- 如果节点是Leader,它将接受这个Command,将其附加到其自己的日志Log中,并启动整个复制流程。
这符合我们之前的谈到的设计,Leader负责所有的写操作。Leader在得到了集群中多数节点通过后就会Commit这个Command。同样地,节点间的通信也是通过AppendEntries RPC实现的。
Leader逻辑
- 接收上层Client的Command,将其附加到自己的日志中。
- 向其他节点发送AppendEntries RPC,将这个Command同步给其他节点。
- 如果其他Follower节点确认了请求,则说明Follower的日志和Leader的日志一致,Leader维护并更新Follower对应的nextIndex和matchIndex。
- 此处如果响应了False,则存在三种情况,具体逻辑可以先按住不表:
- The Follower’s log is shorter than the Leader’s log, the Leader decrements the nextIndex to XLen.
- The Follower’s log contains an entry with a different term (Xterm) at PrevLogIndex, it sets its nextIndex to the last index of the conflicting term in leader's logs plus 1.
- However, if the Leader doesn't have the entry with the conflicting term, it sets the nextIndex to XIndex.
- 此处如果响应了False,则存在三种情况,具体逻辑可以先按住不表:
Follower逻辑
- 接收Leader的AppendEntries RPC,更新心跳时间,验证任期Term并在必要时更新任期。(注意改点很重要,同步也是在选举后进行的,此时必须保证接收到的RPC附带的任期和自己的任期一致,排除收到过期消息的可能)
- Folllower做日志一致性的检查,检查自己的
log[PrevLogIndex]的日志是否和PrevLogTerm(Leader发过来的)一致,此处也会引出如下情况:- If the Follower’s log is shorter than the Leader’s log, it returns Success = False, Xterm = -1,and XLen = log length.
- If the term of the log entry at PrevLogIndex does not match PrevLogTerm, the Follower identifies the conflicting term and the index of the first entry with that term.
- Follower需要处理冲突的日志数据,删除冲突日志和其后的所有日志。
- Follower会将Leader的日志中自己未同步的部分追加到自己的日志中。
- Follower更新自己的commitIndex, 取日志最大的index和Leader的commitIndex的最小值。
具体实现
注意下图中的State machine不是Raft的一部分,但Raft会保证所有节点的State machine都拿到相同的Command序列。
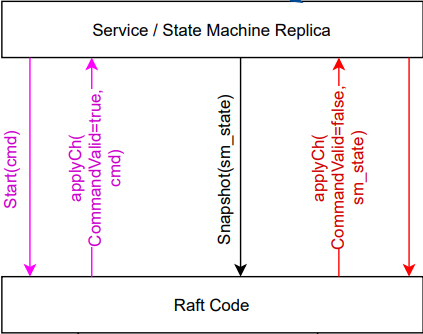
Start函数由客户端调用,写入新Command。如果该节点是Leader,它会将这个Command追加到日志中。
// in raft.go
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -1
term := -1
isLeader := true
// Your code here (2B).
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != Leader {
isLeader = false
} else {
entry := LogEntry{Term: rf.currentTerm, Command: command}
rf.log = append(rf.log, entry)
index = rf.globalLastLogIndex()
term = rf.currentTerm
logger.Printf(rf, Start, "Received command %v,index %v, current log %v", command, index, rf.log)
rf.persist()
}
return index, term, isLeader
}ApplyWorker()将已经Committed的Command应用到状态机,通过go的channel发送消息。
// in apply.go
func (rf *Raft) ApplyWorker() {
// Check if there are any new logs to commit
for !rf.killed() {
// avoid get lock too frequently, otherwise it will slow down the system
if rf.commitIndex <= rf.lastApplied {
time.Sleep(time.Duration(CommitCheckInterval) * time.Millisecond)
continue
}
rf.mu.Lock()
startLastApplied := rf.lastApplied
// If commitIndex > lastApplied: increment lastApplied, apply log[lastApplied] to state machine(§5.3)
for rf.commitIndex > rf.lastApplied {
if rf.lastApplied != startLastApplied {
break
}
rf.lastApplied += 1
msg := &ApplyMsg{
CommandValid: true,
Command: rf.log[rf.toLocalIndex(rf.lastApplied)].Command,
CommandIndex: rf.lastApplied,
}
logger.Printf(rf, Apply, "apply log index %v command %v, current log %v", msg.CommandIndex, msg.Command, rf.log)
rf.mu.Unlock()
rf.applyCh <- *msg
rf.mu.Lock()
}
rf.mu.Unlock()
}
}日志复制
一些关键字段,主要是Leader的视角:
- nextIndex[] : 对于每个节点,应该发送到该节点的下一个日志的索引(初始化为Leader最后日志索引 + 1)
- matchIndex[] : 对于每个节点,已知已同步到节点上的最高日志条目索引(初始化为 0,单调递增)
- prevLogIndex : (AppendEntries RPC 的参数) 新日志之前的日志索引,也就是nextIndex - 1
nextIndex[] 和 matchIndex[] 在选举结束后重新初始化:
// a piece of rf.gatherVote() in vote.go
rf.state = Leader
// nextIndex: initialized to leader last log index + 1
// matchIndex: initialized to 0, increases monotonically
for i := 0; i < len(rf.nextIndex); i++ {
rf.nextIndex[i] = rf.globalLastLogIndex() + 1
rf.matchIndex[i] = rf.lastIncludedIndex
}
logger.Printf(rf, StateChange, "becomes leader")
rf.mu.Unlock()
go rf.SyncLogHeartbeat()AppendEntriesArgs
// in appendEntries.go
type AppendEntriesArgs struct {
Term int // leader’s term
LeaderId int // so follower can redirect clients
PrevLogIndex int // index of log entry immediately preceding new ones
PrevLogTerm int // term of prevLogIndex entry
Entries []LogEntry // log entries to store (empty for heartbeat; may send more than one for efficiency)
LeaderCommit int // leader’s commitIndex
}如果有新的日志需要同步到Follower,Leader将通过心跳机制在 SyncLogHeartbeat() 函数中将新日志发送给Follower。
// in heartbeat.go
func (rf *Raft) SyncLogHeartbeat() {
for !rf.killed() {
rf.mu.Lock()
// if the server is dead or is not the leader, end the loop
if rf.state != Leader {
rf.mu.Unlock()
return
}
for serverId := 0; serverId < len(rf.peers); serverId++ {
if serverId == rf.me {
continue
}
prevLogIndex := rf.nextIndex[serverId] - 1
args := &AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevLogIndex,
LeaderCommit: rf.commitIndex,
}
// codes ...
if rf.isNewLogToReplicate(serverId) {
args.PrevLogTerm = rf.log[rf.toLocalIndex(prevLogIndex)].Term
logger.Printf(rf, Replicate, "sending new log to server %v, args=%v", serverId, args)
args.Entries = rf.log[rf.toLocalIndex(rf.nextIndex[serverId]):]
go rf.handleAppendEntries(serverId, args)
}
rf.mu.Unlock()
time.Sleep(time.Duration(HeartbeatTimeout) * time.Millisecond)
}
}AppendEntriesReply
// in appendEntries.go
type AppendEntriesReply struct {
Term int // currentTerm, for leader to update itself
Success bool // true if follower contained entry matching prevLogIndex and prevLogTerm
XTerm int // term of the conflicting entry
XIndex int // index of the first entry with the conflicting term
XLen int // length of raft.log
}
Follower 接收新的日志并在 AppendEntries() 函数中更新他们的日志。 回顾一下论文的要求:
- Reply false if term < currentTerm (§5.1)
- Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3)
- If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it (§5.3)
- Append any new entries not already in the log
- If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
逻辑总的来说可以概括为,Follower以Leader的日志为准,删除自己和Leader不一样的,并将Leader的日志追加到自己的日志中。问题啥,如果Follower的日志和Leader的日志不一致怎么办,最简单的方法就是逐步回退nextIndex,直到找到和Leader相同的地方,然后Follower从这个位置开始删除冲突数据,并追加Leader的日志。简单来说可以这样实现:
if reply.Term == rf.currentTerm && rf.state == Leader {
// If AppendEntries fails because of log inconsistency: decrement nextIndex and retry
rf.nextIndex[serverId] -= 1
rf.mu.Unlock()
return
}实际上,这样做很慢,所以我们需要使用快速回退(Fast backup)。这里引入三个字段:
XTerm int // term of the conflicting entry
XIndex int // index of the first entry with the conflicting term
XLen int // length of raft.log从Follower角度来看,整体逻辑如下:
// in appendEntries.go
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
defer rf.mu.Unlock()
rf.lastHeartBeat = time.Now()
// 1. Reply false if term < currentTerm (§5.1)
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
reply.Success = false
return
}
// If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1)
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.votedFor = -1
rf.state = Follower
rf.persist()
}
reply.Term = rf.currentTerm
logger.Printf(rf, Replicate, "same term, receive append entries from leader %v, args %v", args.LeaderId, args)
// 2. Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3)
if args.PrevLogIndex > rf.globalLastLogIndex() {
reply.XTerm = -1
// node's log is too short, reply its log length to leader
reply.XLen = rf.toGlobalIndex(len(rf.log))
reply.Success = false
return
} else if rf.log[rf.toLocalIndex(args.PrevLogIndex)].Term != args.PrevLogTerm {
reply.XTerm = rf.log[rf.toLocalIndex(args.PrevLogIndex)].Term
_, reply.XIndex = rf.firstIndexOfTerm(reply.XTerm, rf.toLocalIndex(args.PrevLogIndex))
reply.Success = false
return
}
// 3. If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it (§5.3)
entriesOffset := rf.toLocalIndex(args.PrevLogIndex) + 1
entriesIndex := 0
for logIndex := entriesOffset + entriesIndex; logIndex < len(rf.log) && entriesIndex < len(args.Entries); {
if rf.log[logIndex].Term != args.Entries[entriesIndex].Term {
// delete the conflicting entry and all that follow it
rf.log = rf.log[:logIndex]
break
}
entriesIndex++
logIndex++
}
// 4. Append any new entries not already in the log
rf.log = append(rf.log, args.Entries[entriesIndex:]...)
rf.persist()
reply.Success = true
// 5. If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
if args.LeaderCommit > rf.commitIndex {
rf.commitIndex = Min(args.LeaderCommit, rf.globalLastLogIndex())
logger.Printf(rf, Replicate, "accept log, commitIndex updated to %v, current log %v", rf.commitIndex, rf.log)
}
rf.persist()
}我们逐步解释这个逻辑,首先,我们需要确保请求中PrevLogIndex字段比于Follower的日志最大的索引要大: if args.PrevLogIndex > rf.globalLastLogIndex()。
- 如果条件不成立,这意味着Follower的日志太短。在这种情况下,我们设置
reply.XTerm = -1和reply.XLen = rf.toGlobalIndex(len(rf.log)),用来通知Leader,Leader就可以设置rf.nextIndex[serverId] = reply.XLen。 - 如果条件成立,则我们需要判断对应位置的Term是否一致:
if rf.log[rf.toLocalIndex(args.PrevLogIndex)].Term != args.PrevLogTerm,如果不相同,则返回Follower日志中该Term的第一条日志Index,对于Leader来说:- The Leader sets its nextIndex to the last index of the conflicting term in leader's logs plus 1: rf.nextIndex[serverId] = rf.toGlobalIndex(lastIndex) + 1.
- However, if the Leader doesn't have the entry with the conflicting term, it sets the nextIndex to XIndex: rf.nextIndex[serverId] = reply.XIndex.
- 第二条比较好理解,如果Leader没有这个冲突的Term,那么Follower应该删掉哪些日志,那就是这个Term的所有日志,所以Follower的nextIndex应该设置为XIndex。
- 对于第一条来说,因为Leader和Follower都拥有这个Term,但是不知道具体这个Term从哪里开始了冲突,直接设置为
rf.toGlobalIndex(lastIndex) + 1,从这里重新进行一次尝试,能更快同步到日志。
这是Follower的逻辑:
// a piece of rf.AppendEntries() in appendEntries.go
// 2. Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3)
if args.PrevLogIndex > rf.globalLastLogIndex() {
reply.XTerm = -1
// node's log is too short, reply its log length to leader
reply.XLen = rf.toGlobalIndex(len(rf.log))
reply.Success = false
return
} else if rf.log[rf.toLocalIndex(args.PrevLogIndex)].Term != args.PrevLogTerm {
reply.XTerm = rf.log[rf.toLocalIndex(args.PrevLogIndex)].Term
_, reply.XIndex = rf.firstIndexOfTerm(reply.XTerm, rf.toLocalIndex(args.PrevLogIndex))
reply.Success = false
return
}这是Leader的逻辑:
if reply.Term == rf.currentTerm && rf.state == Leader {
logger.Printf(rf, Replicate, "handle conflict, current log %v,lastInclude Index %v", rf.log, rf.lastIncludedIndex)
// If AppendEntries fails because of log inconsistency: decrement nextIndex and retry
if reply.XTerm == -1 {
rf.nextIndex[serverId] = reply.XLen
} else {
found, lastIndex := rf.lastIndexOfTerm(reply.XTerm, rf.toLocalIndex(rf.nextIndex[serverId])-1)
if found {
rf.nextIndex[serverId] = rf.toGlobalIndex(lastIndex) + 1
} else {
rf.nextIndex[serverId] = reply.XIndex
}
}
rf.mu.Unlock()
return
}总结
在Raft中,只有Leader可以接收到Command,然后将其附加到自己的日志中。Leader通过AppendEntries RPC将这个Command同步给其他节点。Follower接收到Leader的日志后,会根据Leader的日志进行日志一致性检查,如果发现不一致,Follower会删除冲突的日志,并将Leader的日志追加到自己的日志中。使用快速回退,Leader会根据Follower的返回结果来更新自己的nextIndex,以便更快地同步日志。和选举类似,当Leader获得了过半节点的确认后,Leader会将这个Command Commit,然后将这个Command应用到State Machine。
商业转载请联系站长获得授权,非商业转载请注明本文出处及文章链接,您可以自由地在任何媒体以任何形式复制和分发作品,也可以修改和创作,但是分发衍生作品时必须采用相同的许可协议。