HTTP协议中的列头阻塞
HTTP各版本差异
HTTP/1.0
- 每个请求建立一次TCP连接:请求-响应后连接关闭,效率较低。
- 无持久连接:默认不复用连接。
- 无Host头:默认每个IP只服务一个网站,不支持虚拟主机(需要扩展支持)。
- 缓存支持简单:通过 Expires 和 Last-Modified 控制缓存。
HTTP/1.1
- 持久连接(Keep-Alive):默认使用持久连接,多个请求可复用一个TCP连接,提升效率。
- 管线化(Pipelining):允许客户端同时发送多个请求,但服务器仍需顺序响应,导致“队头阻塞”(Head-of-Line Blocking)。
- Host头:强制要求Host字段,支持虚拟主机(多个域名共享一个IP)。
- 缓存更灵活:加入 Cache-Control、ETag、Vary 等机制。
- 分块传输编码(Chunked Transfer Encoding):服务器不知道内容长度时可分块发送响应。
HTTP/2
- 二进制协议:HTTP/2 使用二进制帧格式,而非HTTP/1.x的文本格式,解析更高效、更安全。
- 多路复用(Multiplexing):在一个TCP连接中同时发送多个请求和响应,彻底解决队头阻塞问题。
- 头部压缩(HPACK):请求和响应的头部通过压缩减少冗余,提高传输效率。
- 服务器推送(Server Push):服务器可主动推送客户端可能需要的资源,减少加载延迟。
- 更低延迟与更高带宽利用率。
其中有个队头阻塞概念以及Pipelining比较陌生,那么究竟是什么呢,网上已经有好文了,基于 https://calendar.perfplanet.com/2020/head-of-line-blocking-in-quic-and-http-3-the-details/#sec_pipelining 自己再理解一遍。
Pipeling和HOL
管线化是 HTTP/1.1 引入的一个性能优化机制,允许客户端在同一个 TCP 连接上连续发送多个请求,而不必等待每个请求的响应返回后再发下一个。
虽然请求可以“排队发送”,但服务器的响应必须按照请求的顺序依次返回。浏览器对 HTTP/1.1 的管线化(pipelining)普遍禁用或限制。

因为后续请求的响应必须在前面的响应完成之后才到达,一旦前面出现耗时的响应,那么就会严重阻塞后续的响应,这就是队头阻塞的基本概念。但是需要注意,虽然这里没有启用pipeling,但是浏览器还是会并发发起多个TCP连接来获取数据的,并不会串行请求。
HTTP1.1的限制
HTTP/1.1 是纯文本协议,它无法在一个 TCP 连接中同时区分多个资源的边界。它只靠 headers + Content-Length 来告诉浏览器:“接下来是这个资源的 body”,但它不能嵌套或并列多个资源。
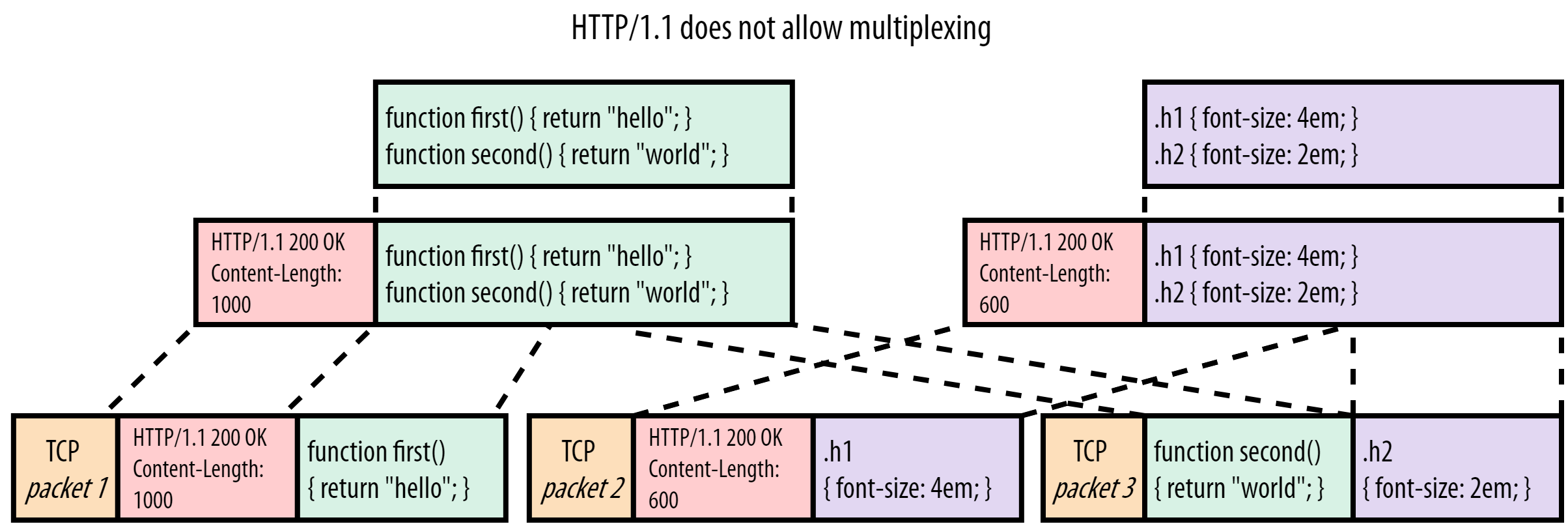
- TCP 第一个包只带来了 450 字节的 JS 内容。
- 第二个 TCP 包中来了另一个文件(style.css)的 headers 和内容,但这时浏览器还在等 script.js 的剩下 550 字节。
- 浏览器不知道有个新的资源开始了,把 CSS 文件的 headers 当成 JS 的一部分读取了。
- 读取满了 1000 字节后,发现“内容不对劲”(解析错误)——因为中间混进了 CSS 的 headers 和内容。
- 这时浏览器试图继续解析“第二个 JS chunk”,但数据已错乱,TCP 包后面数据也得丢弃。
HTTP2的解决方案
HTTP/2 是一个二进制协议,不再是文本协议。
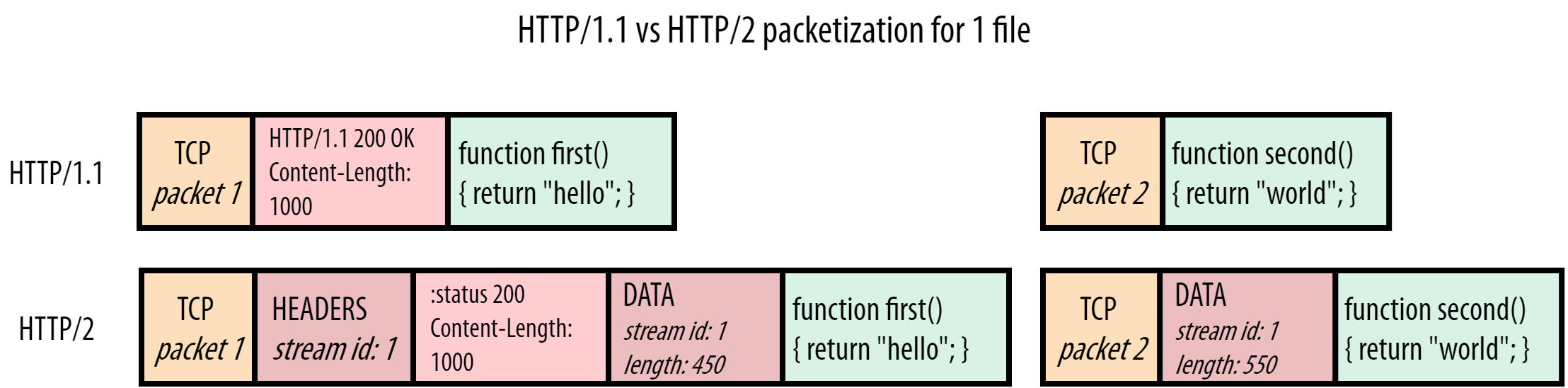
通过添加DATA帧,所有请求/响应都通过这个 Stream ID 拆分成独立的“流”(Stream)。浏览器和服务器可以并发交错地发送帧,只要 Stream ID 不同,接收方就能正确归类。
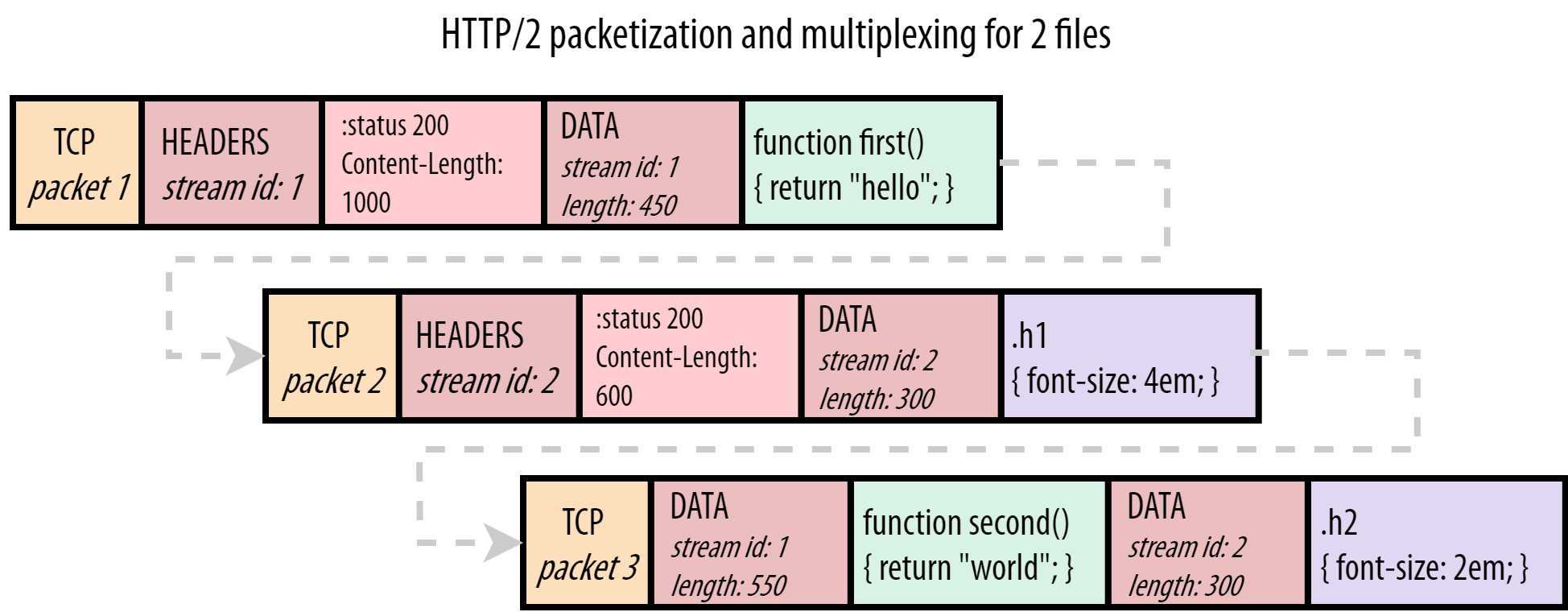
HTTP2允许通过 “权重”和“依赖关系” 配置好帧应该如何交错。
通过这种交错的方式,我们能够允许哪怕是在后续请求的内容,也能够在前一个内容未准备完成时就有相应到客户端的机会。
HTTP3的解决方案
我们在应用层解决了队头阻塞,但是在TCP中还没有。
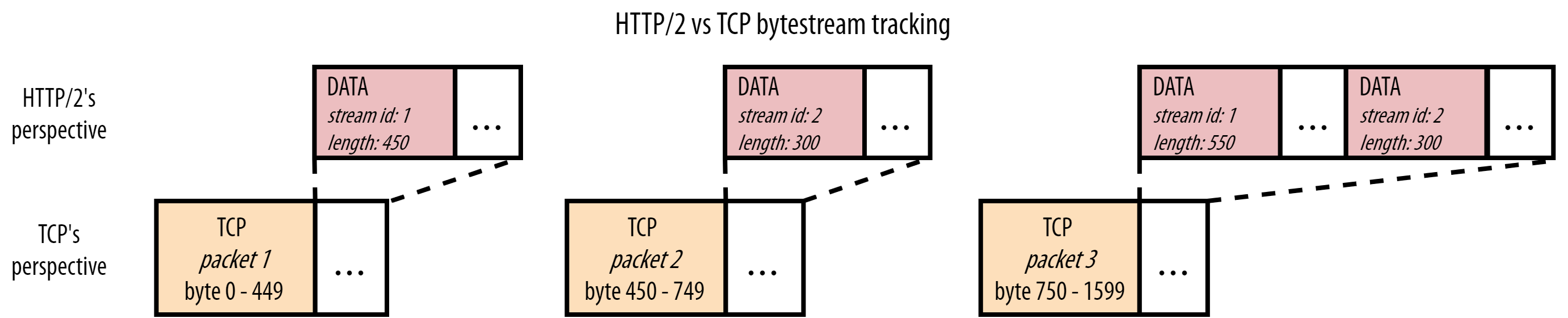
如果中间的TCP包丢失了,那么后续的TCP包也是不能传递给应用层的,这也是某种程度的队头阻塞。所以HTTP3实际上引入了QUIC。
QUIC
QUIC(Quick UDP Internet Connections)是 Google 发明的一个基于 UDP 的新传输协议。
HTTP/3 是基于 QUIC 协议构建的 HTTP 协议版本。
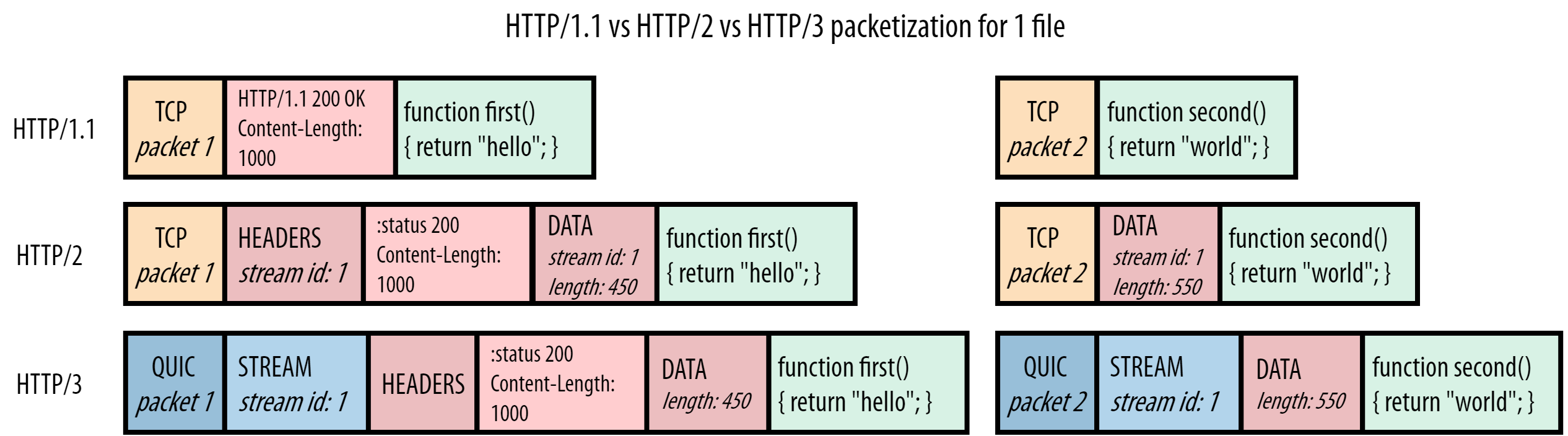
HTTP3把HTTP2引入的Stream id引到了QUIC这一层去处理。
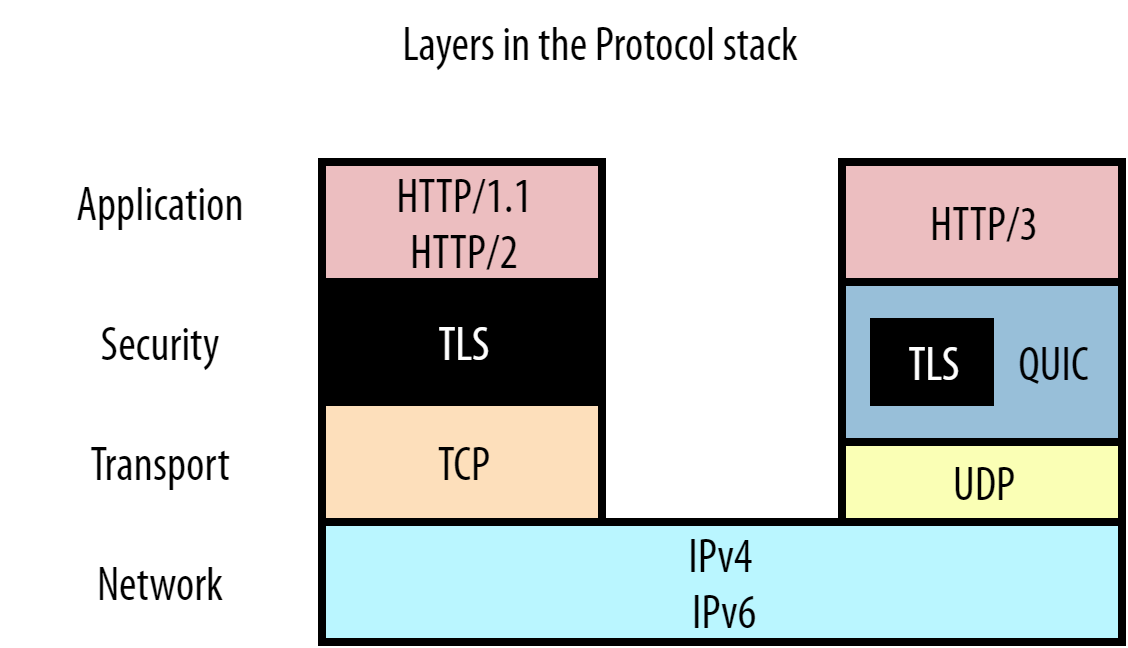
整个结构大致如上。那么如果下面第二个QUIC包丢失会怎么样呢
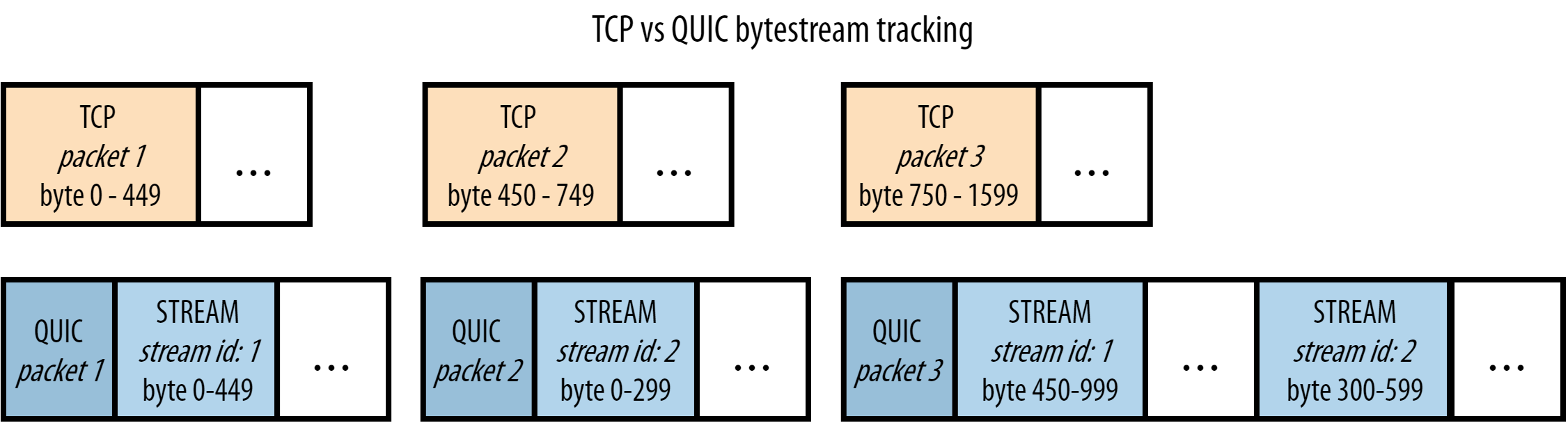
类似于 TCP,QUIC 中数据包 1 的 stream 1 数据可以直接传递给浏览器处理。但在处理数据包 3 时,QUIC 展现出了比 TCP 更智能的一面:
它会检查 stream 1 的字节范围,发现该 STREAM 帧正好紧接在之前的帧之后(字节 450 紧跟字节 449,没有任何缺口),因此可以立即将这些数据交付给浏览器。
然而,对于 stream 2 来说,情况不同。QUIC 发现该 STREAM 帧前面存在缺失(字节 0–299 尚未收到,这部分数据原本包含在丢失的数据包 2 中)。因此,QUIC 会暂时保留这段数据,直到数据包 2 被成功重传。
相比之下,TCP 则会一视同仁地等待缺失的数据到达——即使数据包 3 中包含的是连续的流 1 数据,它也不会交付给浏览器,而是一并阻塞。
潜在问题
首先,对于多个流来说,每个流内部的包仍然是顺序的,也就是说,当我们仅考虑其中某一个流时,如果流中间的某个包丢了,我们后续该流的包仍然触发了阻塞。理想的情况应该是,我们能够乱序发送,然后在接收端再拼接起来,这样我们真正消除了阻塞。
其次,网络中的丢包往往是在一个时间段内发生,不同的交错策略会导致不同的结果。
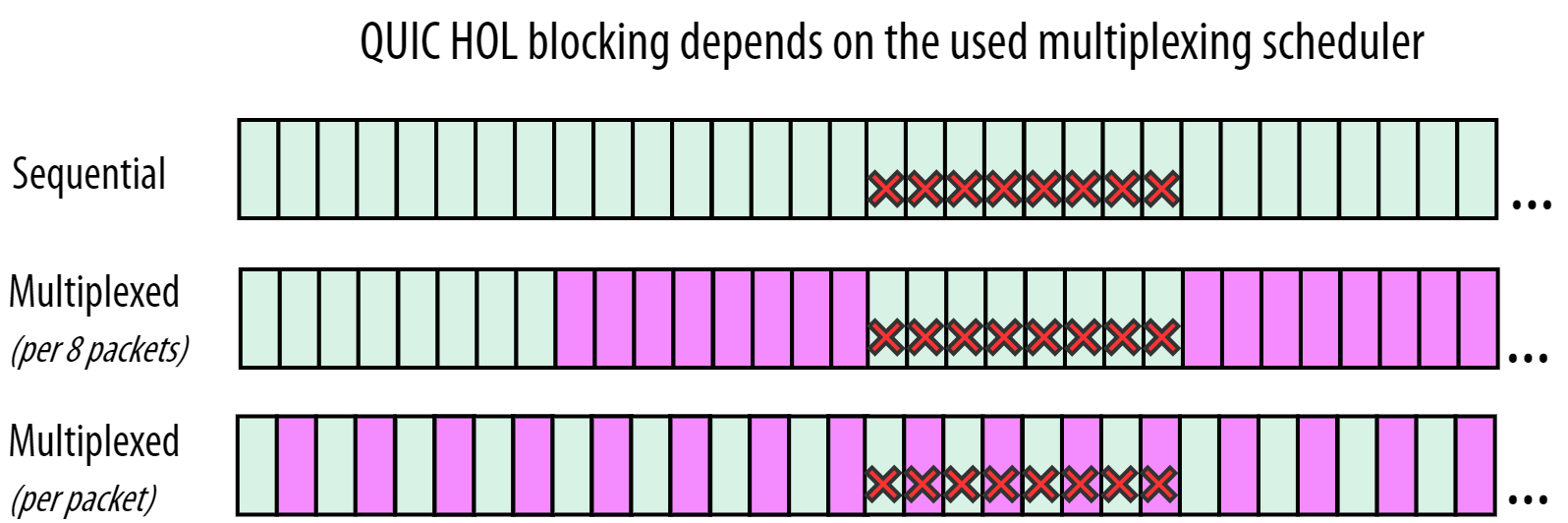
对于第二行,我们仍然能够接收紫色的流的数据,因为紫色的流的数据包是完整的,没有丢包。而对于第三行,我们将被迫等待中间的数据重发。
商业转载请联系站长获得授权,非商业转载请注明本文出处及文章链接,您可以自由地在任何媒体以任何形式复制和分发作品,也可以修改和创作,但是分发衍生作品时必须采用相同的许可协议。